搜广推实习知识储备Day1
本文依托FunREC项目展开 ## 快速候选召回 ### 协同过滤 #### 物品协同过滤 1. itemCF:用户的兴趣具有一定的连贯性,喜欢某个物品的用户往往也会对相似的物品感兴趣。
为每个用户维护一个交互过的物品列表,维护物品共现矩阵,计算物品间相似度($\frac{公共用户}{\sqrt{两个物品交互用户数之积}}$);
先根据最近交互物品(几百个)生成各自的相似物品(Top-10),然后计算对这些物品各自兴趣强度($相似度\times 兴趣强度$)Swing算法(相似度优化算法):如果多个用户在其他共同购买行为较少的情况下,同时购买了同一对物品,那么这对物品之间的关联性就更可信;
构建用户-物品二部图,再计算物品之间的Swing Score,对于与\(i\),\(j\)物品共现的用户,任意两个用户的物品集合的交集的倒数,作为这一对用户对于\(i\),\(j\)相似度贡献值。有时在分母上加一个平滑系数\(\alpha\) >

- Surprise算法(互补商品推荐):真正的互补关系主要发生在不同商品类别之间,且购买时间间隔越短,互补性越强
用户协同过滤
- UserCF:具有相似历史行为的用户,未来偏好也相似 类似ItermCF,计算用户相似度;系统为目标用户找到最相似的K个用户作为“相似用户集合”(通常K=50-200)。然后收集这些相似用户交互过的所有物品作为候选集合,并计算目标用户对候选物品的兴趣分数:
矩阵分解
协同过滤存在一个挑战:数据稀疏性。在真实的推荐场景中,用户-物品交互矩阵往往是极度稀疏的——大部分用户只与极少数物品发生过交互。
这导致两个问题:一是很难找到足够的共同评分来计算可靠的相似度;二是即使找到了相似用户或物品,他们的交互覆盖面也可能很有限。 1. FunkSVD基础模型:把用户-物品评分矩阵(\(m\times n\))分解为用户矩阵(\(m \times \mathcal{K}\) )(\(\mathcal{K} \times n\)),\(\mathcal{K}\)表示因子数量。
那么就需要通过 梯度下降法 \(\min \bigg ( \frac{1}{2}\sum\big(\text{评分矩阵}_{i,j}-\text{用户矩阵}\cdot \text{物品矩阵}_{i,j}\big)^2 \bigg)\),通常还会添加L2正则来防止过拟合
- BiasSVD(去除偏差): 不同用户的评分习惯差异很大。有些用户天生就是“好人”,很少给低分;有些用户则比较严格,平均分都不高。同样,有些电影因为制作精良或者明星云集,普遍得到较高评分;而有些冷门或质量一般的电影则评分偏低。
向量召回
I2I召回
Word2Vec: Word2Vec主要包含两种模型架构:Skip-Gram和CBOW(Continuous Bag of Words)。Skip-Gram模型通过给定的中心词来预测其周围的上下文词,而CBOW模型则相反,通过上下文词来预测中心词。在推荐系统中,Skip-Gram模型由于其更好的性能表现而被更广泛地采用。
Skip-Gram模型的目标是最大化其上下文窗口内所有词语的出现概率
Item2Vec:在推荐系统中,每个用户的交互历史可以看作一个“句子”,其中包含的物品就是“词语”。如果两个物品经常被同一个用户交互,那么它们之间就存在相似性。
EGES(Enhanced Graph Embedding with Side Information):该方法通过两个关键创新来改进传统的序列建模:一是基于会话构建更精细的商品关系图来更好地反映用户行为模式,二是融合商品的辅助信息来解决冷启动问题。
EGES的第一个创新是将物品序列的概念从简单的用户交互扩展为更精细的会话级序列
当两个商品在同一会话(时间窗口内)的用户行为序列中连续出现时,在它们之间建立一条有向边,边的权重等于这种商品转移模式在所有用户行为历史中出现的频率。相比于传统方法将整个用户历史视为一个序列,这种基于会话的图构建方法能够更准确地捕捉用户在特定时间段内的连续兴趣转移模式。 >
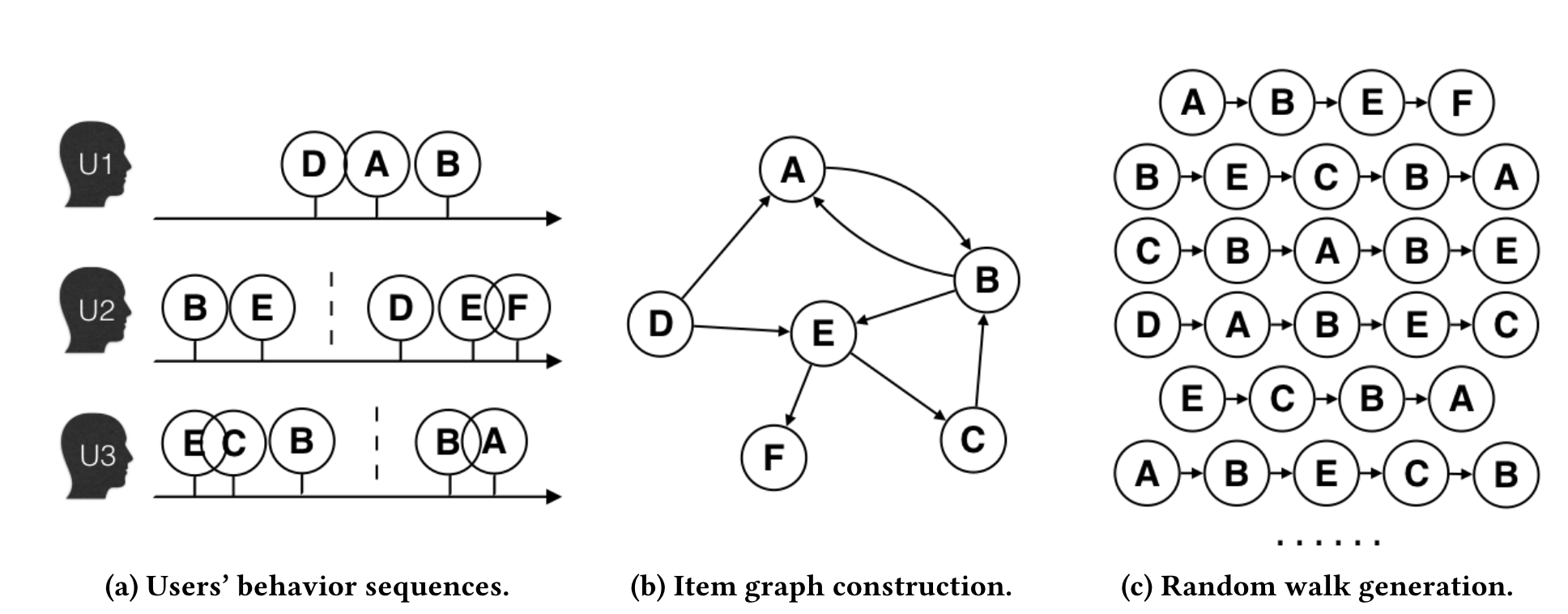
EGES方法的第二个创新是引入商品的辅助信息(如类别、品牌、价格区间等)来增强商品的向量表示
U2I召回
如果说I2I召回解决的是“买了这个商品的人还会买什么”的问题,那么U2I召回直面的则是推荐系统的核心命题——“这个用户会喜欢什么商品”。 1. FM(Factorization Machine)因子分解机
FM 的完整表达式如下:
$$\hat{y}(\mathbf{x}) := w_0 + \sum_{i=1}^{n} w_i x_i + \sum_{i=1}^{n} \sum_{j=i+1}^{n} \langle \mathbf{v}_i, \mathbf{v}_j \rangle x_i x_j$$
这个公式由三部分组成:
1. **偏置项 ($w_0$)**:模型的全局基准分。
2. **一阶线性项 ($\sum w_i x_i$)**:每个特征独立对结果的影响。
3. **二阶交叉项 ($\sum \sum \langle \mathbf{v}_i, \mathbf{v}_j \rangle x_i x_j$)**:这是 FM 的核心。 它不再为每一对交叉特征单独学习一个权重 $w_{ij}$,而是为每个特征 $i$ 学习一个**隐向量 (Latent Vector)** $\mathbf{v}_i$。特征 $i$ 和 $j$ 的交互权重由这两个隐向量的内积 $\langle \mathbf{v}_i, \mathbf{v}_j \rangle$ 决定。
原本计算二阶项需要 $O(n^2)$ 的复杂度(遍历所有两两组合),在特征极其稀疏的情况下计算量巨大。
下面展示了一个数学技巧,将复杂度降到了 $O(kn)$:
$$\sum_{i=1}^{n} \sum_{j=i+1}^{n} \langle \mathbf{v}_i, \mathbf{v}_j \rangle x_i x_j = \frac{1}{2} \sum_{f=1}^{k} \left( \left( \sum_{i=1}^{n} v_{i,f} x_i \right)^2 - \sum_{i=1}^{n} v_{i,f}^2 x_i^2 \right)$$
通过这个变换,原本需要“两两点积”的操作变成了“先求和再平方”,极大提升了训练效率。
---
FM 与双塔模型的关系
双塔模型可以看作是 **FM 在召回场景下的工程化形态**。
核心推导逻辑
1. **特征分组**:将特征分为用户侧特征 ($U$) 和物品侧特征 ($I$)。
2. **忽略常数项**:在召回阶段,我们是为一个固定用户去挑选上万个物品。由于用户特征是固定的,**用户内部特征的交互分**对于所有候选物品都一样,不影响排序,因此在计算 score 时可以忽略。
3. **重新组织公式 (2.2.15)**:通过数学变形,剩下的项(物品一阶项、物品内二阶项、用户-物品交叉项)可以重新整理为两个向量的内积:
$$score_{FM} = V_{item} \cdot V_{user}^T$$
* **用户塔 ($V_{user}$)**:只包含用户特征的聚合表示。
* **物品塔 ($V_{item}$)**:包含物品特征的聚合以及物品自身的内部交互。
---
通俗例子:相亲市场的“打分表”
想象一个相亲场景:
* **线性模型(没有交叉)**:只看硬指标。你有房加 10 分,你性格好加 5 分。分高就在一起。
* **传统二阶交叉($w_{ij}$)**:模型需要死记硬背。它得记住“上海户口”和“喜欢吃辣”的人在一起会多加 3 分。由于组合太多,模型可能根本没见过某些组合(数据稀疏),就没法打分。
FM 的方式(隐向量)
每个人(特征)都有一个“性格标签向量”。
* **男生特征“程序员”**:隐向量是 `[高薪: 0.9, 加班: 0.8, 浪漫: 0.1]`。
* **女生特征“教师”**:隐向量是 `[稳定: 0.9, 有耐心: 0.8, 浪漫: 0.5]`。
FM 不用死记“程序员”配“教师”的具体得分,它只需计算这两个向量的匹配度(内积)。即便模型从没见过这一对组合,只要见过程序员和其他人的搭配,它就能学好这个向量。
双塔模型的方式(召回加速)
在有 1 亿人的相亲库里,给每个男生实时算一遍 FM 太慢了。
1. **用户塔**:先把这个男生的所有特征扔进一个黑盒,算出一个终极“择偶偏好向量” $\mathbf{V}_{user}$。
2. **物品塔**:把所有女生的特征也分别算成“个人魅力向量” $\mathbf{V}_{item}$。
3. **匹配**:最后只需做简单的内积计算(向量检索),就能从 1 亿人里瞬间揪出最匹配的那几个。DSSM(Deep Structured Semantic Model):深度结构化语义模型 > 虽然FM在数学上优雅地实现了向量分解,但它本质上仍是线性模型,对于复杂的非线性用户-物品关系表达能力有限

- 模型结构:它将特征划分为“用户侧(User)”和“物品侧(Item)”两组。每一侧通过独立的深度神经网络(DNN)进行非线性变换,将复杂的原始特征压缩成两个等维度的稠密向量(Embedding)。
- 交互机制:两塔在底层完全解耦,仅在最终输出层通过内积(Dot Product)或余弦相似度计算匹配分 \(s(x, y)\)。这种设计实现了“特征的复杂交叉在塔内,跨塔的交互在末端”的范式。
- 工程优势:由于两塔不共享底层参数,物品向量可以离线预计算并存储在向量数据库中。线上请求时,仅需实时计算用户向量,再通过 ANN(近似最近邻检索)在大规模物料库中实现毫秒级召回。
- 训练优化:为了保证训练与检索的一致性,DSSM 通常配合 L2 归一化 将内积转化为欧式距离度量,并引入温度系数 \(\tau\) 来放大正负样本的区分度,使模型对高分样本更“敏感”。
【通俗例子:外卖平台的“口味匹配”】
想象你在用一个外卖 App:
- 用户塔(你):收集你的近期订单、搜索偏好、地理位置。经过神经网络计算,把你抽象成一个向量,比如:
[爱吃辣: 0.9, 消费力: 0.2, 距离要求: 0.8]。 - 物品塔(商家):收集店家的菜系、评价、人均价格。店家也被抽象成向量,比如:
[川菜: 0.95, 昂贵: 0.1, 距离: 0.7]。 - 匹配(下单):App 不需要当你点开每个商家时才去现算“你俩合不合”,而是直接拿你的向量去匹配库里已经存好的千万个商家向量。两个向量在空间里越接近(角度越小),这个店就越排在前面。 你敏锐地察觉到了它们的核心共同点:在最终打分阶段,它们都使用了“向量点积”。
【严谨的对比分析】
1. 特征交叉的深度(Deep vs. Shallow)
- FM:本质上是一个浅层模型。它的特征交叉仅限于“二阶”,即两个特征之间两两相乘,计算公式是线性的隐向量内积。
- DSSM:是一个深层模型。它利用深度神经网络(DNN)对用户和物品侧的特征进行多层非线性变换。这意味着 DSSM 能学到比 FM 二阶交叉更复杂、更抽象的高阶语义特征。
2. 架构的设计目标(General vs. Decoupled)
- FM:最初的设计是为了解决稀疏数据下的线性回归/分类问题,并没有强制要求区分“用户”和“物品”。它可以是用户特征、物品特征甚至上下文特征全部打散在一起做交叉。
- DSSM:原生就是为检索和召回设计的“双塔”结构。它强制要求将特征分为用户侧和物品侧,且两塔之间在最后一层点积前互不干扰。这种解耦设计是为了实现极其高效的离线计算和在线检索。
3. 计算效率的逻辑
- FM:虽然可以通过数学变形将复杂度降为 \(O(kn)\),但如果要计算用户对海量物品的得分,依然需要逐一计算。
- DSSM:侧重于预计算。物品塔向量 \(v\) 可以完全离线生成并存入向量数据库,线上只需计算一次用户塔向量 \(u\),利用 ANN 检索实现毫秒级响应。
YouTubeDNN:从匹配到预测用户下一行为 > 将召回任务重新定义为“预测用户下一个会观看的视频”。 >

YouTubeDNN采用了“非对称”的双塔架构:用户塔集成了观看历史、搜索历史、人口统计学特征等多模态信息,用户观看的视频ID通过嵌入层映射后进行平均池化聚合,模型还引入了“Example Age”特征来建模内容新鲜度的影响;物品塔则相对简化,本质上是一个巨大的嵌入矩阵,每个视频对应一个可学习的向量,避免了复杂的物品特征工程。
【严谨解释:YouTubeDNN 与 FM/DSSM 的区别】
问题的定义不同:
FM 是在算“用户和物品对不对付”(二阶特征交叉)。
DSSM 侧重于语义空间的匹配,通常是对称结构(用户和物品都经过深层网络)。
YouTubeDNN 则将推荐看作 “预测下一个 Token”。其数学本质是给定用户 \(U\) 和上下文 \(C\),预测观看视频 \(i\) 的概率: \[P(w_t = i | U, C) = \frac{e^{v_i u}}{\sum_{j \in V} e^{v_j u}}\]
架构的“非对称性”:
- DSSM 的物品塔往往也是深层的 DNN。
- YouTubeDNN 采用了非对称结构:用户侧(左塔)非常“重”,融合了观看历史、搜索历史、人口统计学特征等多模态信息;而物品侧(右塔)则非常“轻”,本质上是一个巨大的 Embedding 矩阵,每个视频 ID 对应一个可学习的向量。
特征工程的进化:
- 它引入了 Example Age(样本年龄)特征,解决了视频内容更新快、“模型偏向旧视频”的冷启动痛点。
- 它使用 Mean Pooling 处理变长的用户行为序列,将用户看过的视频 Embedding 取平均作为输入。
【通俗例子:超市导购的进化】
- FM(传统导购):看到你手里拿着咖啡,又看到货架上有砂糖,导购凭借经验告诉你:“咖啡和砂糖很配哦。”(简单的两两关联)。
- DSSM(专业调研员):导购先花 10 分钟研究你的背景,再花 10 分钟研究这瓶水的成分,最后看两者的匹配度。(对称的深度理解)。
- YouTubeDNN(超级预言家):
- 它不管商品背后复杂的成分,它只关注你。它把你过去一年买过的所有东西、搜过的关键词、甚至你的年龄全部塞进脑子里(复杂的用户塔)。
- 它在大脑里形成了一个“你最可能买的东西的长相”描述。
- 然后它直接转身冲向仓库(Embedding 矩阵),在成千上万个商品里,瞬间揪出那个长得最像你大脑描述的商品。
- 关键点:它还记得“喜新厌旧”。如果两个商品一样好,它会优先把刚进货的新品推给你(Example Age)。
【核心对比表:快速梳理】
维度 FM(基础款) DSSM(对称款) YouTubeDNN(工业款) 特征交互 仅限二阶线性交叉 多层非线性深层交叉 极其复杂的用户侧特征融合 物品建模 隐向量 \(v_j\) 深度网络处理后的向量 简单的 Embedding 查表 训练目标 预估点击率 (CTR) 语义空间相似度 预测下一个观看视频 ID 工程技巧 矩阵分解思想 负采样优化 负采样 + 样本年龄 + 时序分割
序列召回
序列召回就是要利用用户行为的时间顺序信息来进行推荐。它的基本想法是:用户的当前兴趣不仅取决于他过去喜欢什么,还取决于他最近在做什么,以及这些行为的顺序。
MIND(Multi-Interest Network with Dynamic Routing):用多个向量捕捉用户的多元兴趣 > 既然用户有多种兴趣,为什么不用多个向量来分别表示呢?就像给每个兴趣爱好都分配一个专门的“代言人”。 >
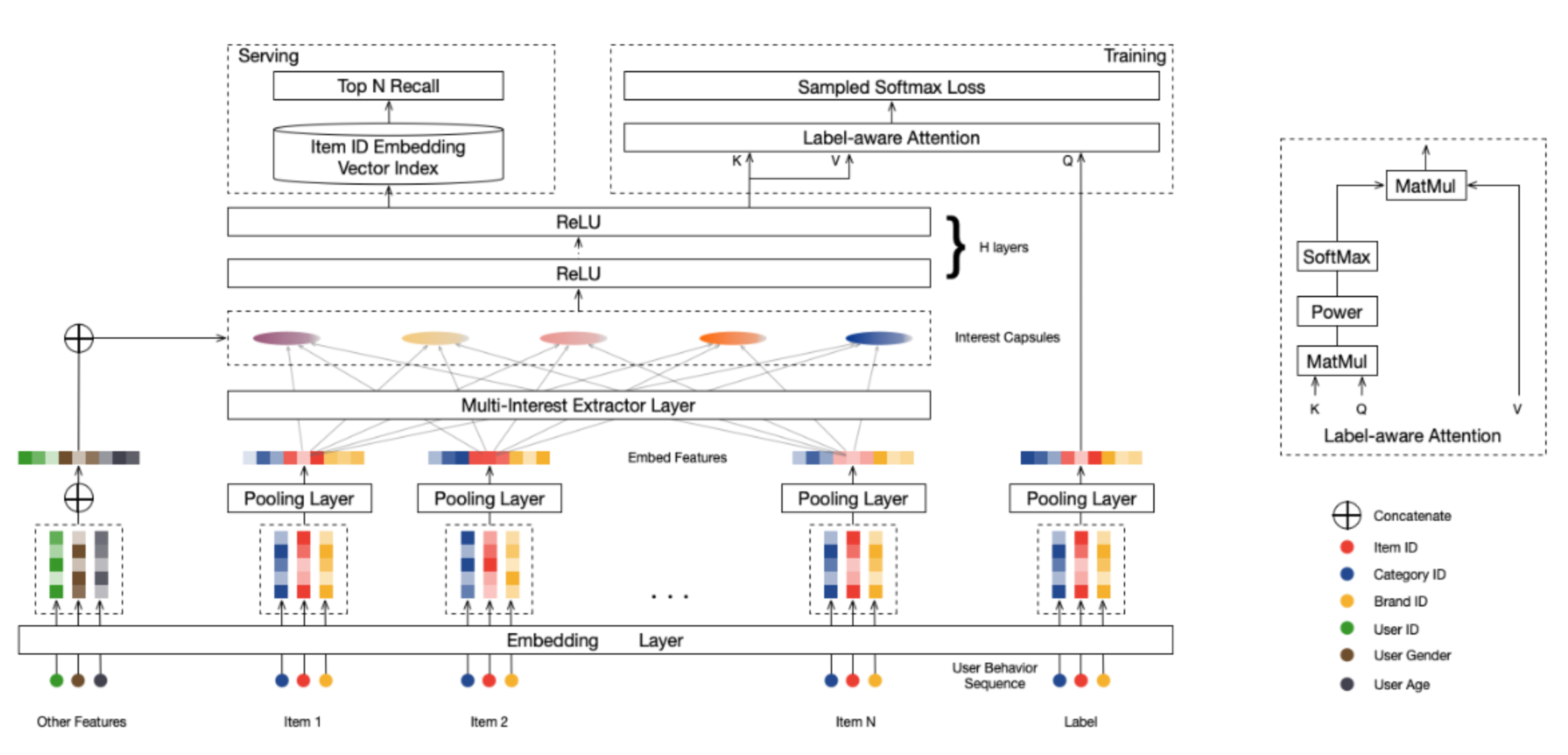 >
从整体架构来看,除了常规的Embedding层,MIND模型还包含了两个重要的组件:多兴趣提取层和Label-Aware注意力层。
>
从整体架构来看,除了常规的Embedding层,MIND模型还包含了两个重要的组件:多兴趣提取层和Label-Aware注意力层。【多兴趣提取层:动态路由(Dynamic Routing)】
严谨解释: 这一层借鉴了胶囊网络(Capsule Network)的思想,核心是通过动态路由算法将用户的历史行为进行“软聚类”。
- 特征映射:利用共享的双线性变换矩阵 \(S\) 将用户历史点击的物品 Embedding 映射到统一的兴趣空间。
- 迭代聚类:通过 3 次左右的迭代更新路由系数 \(b_{ij}\)。在每一轮中,计算物品与各兴趣胶囊的关联度(Softmax),将物品向量加权聚合形成兴趣胶囊 \(z_j\),最后使用 Squash 函数进行非线性压缩,确保向量模长在 \([0, 1)\) 之间,模长代表该兴趣存在的概率。
- 自适应兴趣数:根据用户历史行为的数量,动态调整生成的兴趣胶囊数量 \(K'\),让活跃用户拥有更丰富的兴趣表示。
通俗例子: 想象你在整理一个乱七八糟的衣柜(用户的历史行为)。
- 传统模型(YouTubeDNN):强行把所有衣服塞进一个压缩袋。结果虽然省空间,但西装和泳裤挤在一起,全变形了。
- MIND 的动态路由:相当于给你几个空的收纳箱(兴趣胶囊)。你拿出一件衣服,看看它更像“正装”还是“运动装”,然后把它放进对应的箱子。经过几次调整,你的衣柜就变成了“正装箱”、“运动箱”和“居家箱”。
【Label-Aware 注意力层:标签感知】
严谨解释: 在训练阶段,虽然我们提取了多个兴趣向量,但必须确定哪一个兴趣导致了下一次的点击(即 Label),才能进行反向传播。
- 目标作为查询(Query):将目标商品 \(e_i\) 作为查询向量,与用户生成的多个兴趣胶囊 \(V_u\) 计算相似度。
- 注意力分配:通过公式 \(v_u = V_u \cdot \text{Softmax}(\text{pow}(V_u^T e_i, p))\) 选取最相关的兴趣向量。
- 参数 \(p\) 的作用:\(p\) 是平滑系数。当 \(p\) 很大时,模型会呈现“硬注意力”倾向,即几乎只关注最匹配的那一个兴趣,忽略其他干扰,这能显著加快模型收敛。
通俗例子: 假设你刚才分好了“正装”、“运动”和“居家”三个收纳箱。
- 场景:现在你实际出门去参加了一场“马拉松”(目标商品/Label)。
- 注意力选择:模型会发现你的“马拉松”行为显然和“运动箱”最匹配。于是,它在训练时会重点更新“运动箱”里的参数,而不会去动“正装箱”,因为它知道这次出门跟西装没关系。
【总结:MIND 强在哪?】
- 从 1 到 N:它将用户的表达从“一个点”变成了“多个点”,极大提升了召回的覆盖面和准确度。
- 线上检索:在线上服务时,MIND 会将这 \(K\) 个兴趣向量分别去向量数据库(如 Faiss)中进行检索,最后把结果汇总,这保证了推荐结果的多样性。
既然你已经理解了如何提取多兴趣,需要我为你对比一下 MIND 和阿里后来推出的类似模型(如使用 Self-Attention 的 ComiRec),看看它们在提取多兴趣时有什么不同的“口味”吗?
SDM(Sequential Deep Matching model): 融合长短期兴趣,捕捉动态变化 > MIND解决了兴趣“广度”的问题,但新的问题随之而来:时间。 用户兴趣不仅是多元的,还是动态演化的。一个用户在一次购物会话(Session)中的行为,往往比他一个月前的行为更能预示他下一刻的需求。MIND虽然能捕捉多个兴趣,但并未在结构上显式地区分它们的时效性。 >
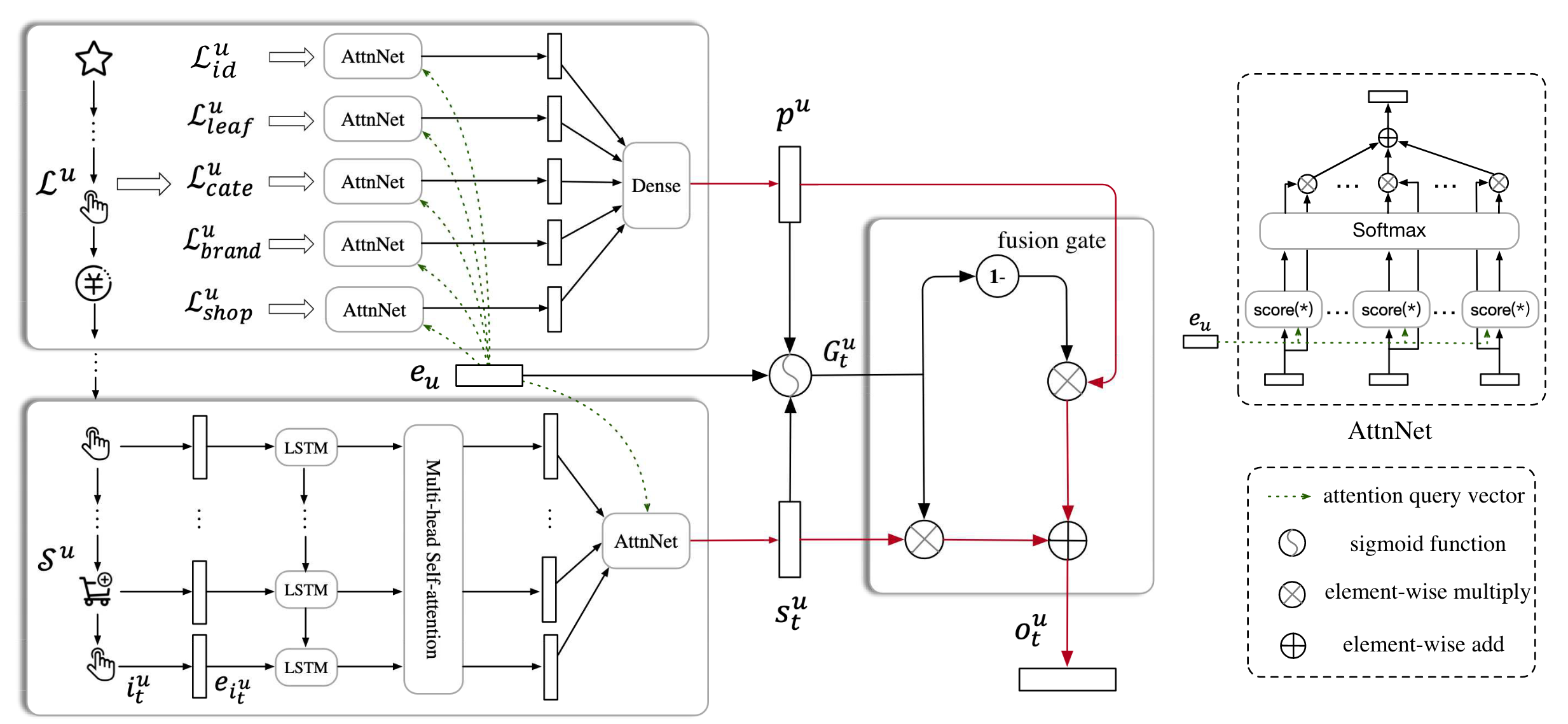
SDM 的核心贡献在于它不仅区分了长短期兴趣,还通过门控机制(Gating)实现了这两者的智能融合,而不是简单的拼接。
【1. 短期兴趣提取:捕捉“当下的冲动”】
原理: SDM 使用了一个三层结构来处理用户当前的会话序列(Session):
- LSTM 层:首先通过 LSTM 学习用户最近点击序列的时序依赖关系。LSTM 的门控机制能有效过滤掉用户偶尔的“手滑”或随机点击带来的噪音。
- 多头自注意力层 (Multi-head Self-Attention):在时序特征基础上,利用多头机制捕捉兴趣的多样性。每个“头”可以专注于不同的兴趣维度(比如一个头关注品牌,一个头关注价格)。
- 个性化注意力层:最后使用用户画像向量 \(e_u\) 作为查询(Query),对多头注意力的输出进行加权聚合,得到最终的短期兴趣表示 \(s_t^u\)。
作用: 精准定位用户此时此刻最想买什么,并排除无关干扰。
【2. 长期兴趣提取:勾勒“稳定的性格”】
原理: 长期行为包含的信息量大但非常杂乱,SDM 采取了“分而治之”的策略:
- 多维度聚类:将用户过去一年的行为按特征子集拆分,如:交互过的商品 ID、子类目、一级类目、店铺、品牌等。
- 注意力聚合:同样利用用户画像向量 \(e_u\) 去在这些维度上计算注意力。模型会从不同维度(如“你最喜欢的品牌”或“你最常去的店铺”)去理解你的长期偏好,最终拼接并通过全连接网络得到长期兴趣表示 \(p^u\)。
作用: 捕捉用户本质上是一个什么样的人,提供稳定的基准偏好。
【3. 长短期融合:智能的“决策阀门”】
原理(核心创新): 简单的拼接或加权求和无法处理长短期兴趣的冲突。SDM 设计了类似 LSTM 的门控融合机制:
- 门控向量 \(G_t^u\):综合输入用户画像 \(e_u\)、短期兴趣 \(s_t^u\) 和长期兴趣 \(p^u\),生成一个 0 到 1 之间的权重向量。
- 融合公式:\(o_t^u = (1 - G_t^u) \odot p^u + G_t^u \odot s_t^u\)。 这意味着,模型可以在每一个特征维度上,自主决定是听“长期的习惯”还是听“短期的冲动”。
作用: 解决“推荐结果被近期点击带跑偏”或“推荐结果太保守”的问题。
【通俗例子:你去超市买年货】
- 长期兴趣 (\(p^u\)):你是个注重健康的人,平时买东西的习惯是“少油少盐”。这是你的底色。
- 短期兴趣 (\(s_t^u\)):刚才你进店后,连续看了 3 盒不同品牌的巧克力,还看了一箱红酒。这说明你现在的意图是“买年货送礼”。
- 门控融合 (\(G_t^u\)):
- 维度 A(健康):门控发现你现在的行为(买巧克力)和长期习惯(健康)冲突。由于你正在选年货,门控会关小长期兴趣的阀门,不再推减脂餐给你。
- 维度 B(品牌偏好):门控发现你虽然在买巧克力,但依然选择了你长期信赖的某个高端品牌。此时门控会打开长期兴趣的阀门,利用你对品牌的忠诚度来精准推荐。